Transformer 解碼器的架構和編碼器雷同,但有兩個主要的差異,第一:解碼器每一層的第一個子層必須執行 Masked 動作;二為:解碼器每一層都多了一個 Multi-Head Attention 子層。
先來看看第二個 Multi-Head Attention 子層,如下圖,它並不是一個 Self-Attention,它的輸入 V 及 K 是來自編碼器的輸出值,而 Q 才是來自第一個子層。因此這一個子層在論文中,有時稱它為 encoder-decoder attention (sub)layer。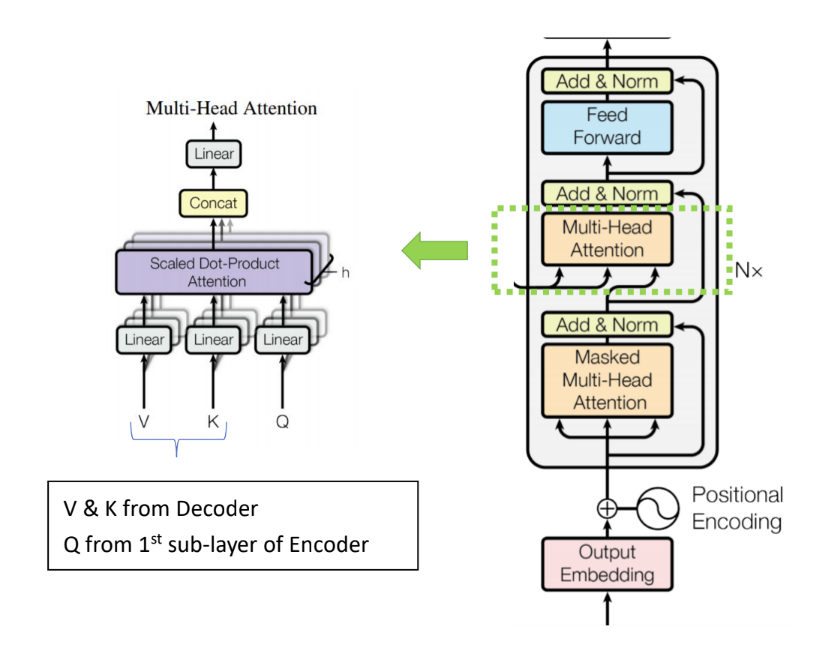
這種設計,在論文中解釋道:其可以讓每一個解碼器子層的輸入值去「關注 (Attend)」編碼器的輸出序列,達到類似於其他 sequence-to-sequence 模型的機制。
In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models.
因為 Transformer 表現太好了,老頭在學習時直接研究它的結構,並沒有花時間去看其他的 sequence-to-sequence 模型,有興趣的 AI 人可以參考(註一)引用的論文。
老頭就由一個將 je suis etudiant 翻譯為 I am a student. 的 Transformer 為例,來說明 Masked Multi-Head Attention 在解碼器中運作的方式。(註二)
首先,編碼器接受句子 je suis etudiant 為輸入序列,產生輸出後再算出各輸出值對應的 K, V 值,這兩個值將會參與解碼器中 encoder-decoder attention 的運算。
此時,解碼器尚未產出任何輸出,所以其輸入為空序列 (NULL sequence),經第一次解碼器運算,產生第一個輸出 I 。如下圖所示。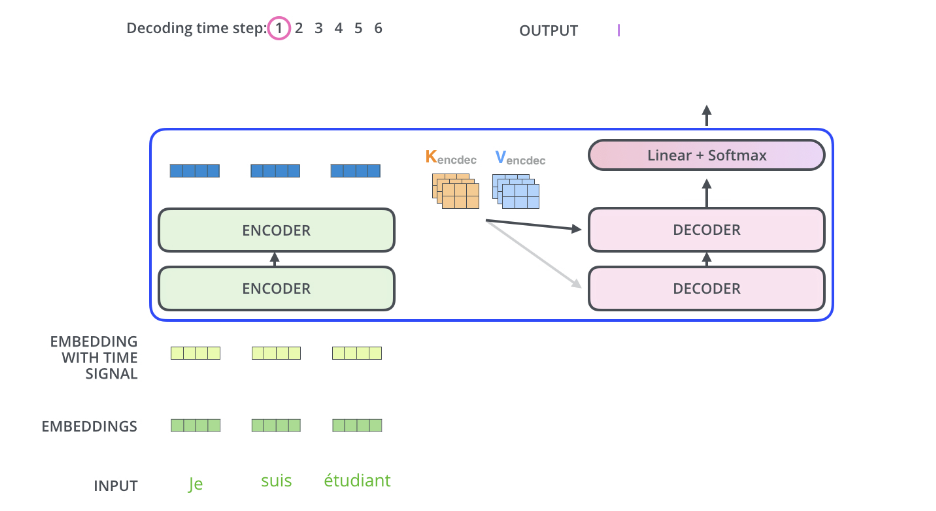
要注意的事,解碼器中每一個 Masked Multi-Head Attention 子層中的 Masked 操作皆要執行,執行的方式是:將 Scaled 輸出序列中的每一個值,皆設為 -Inf (minus infinity)。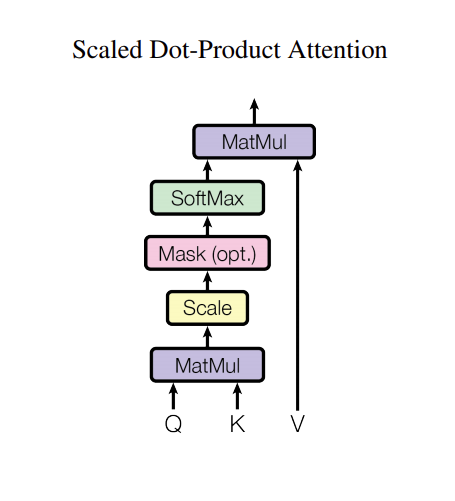
接下來進行解碼器第二次運算,拿第一次輸出「 I 」作為輸入序列的第一個元素,其他輸入元素仍設為空字元(NULL),匯入解碼器,此回,Masked Multi-Head Attention 子層中的 Masked 操作執行的方式是:將 Scaled 輸出序列中的第一個值保持不變,其他皆設為 -Inf (minus infinity),也就是說將對應於輸入為 NULL 的位置的值全設為 -Inf,如此,在 SoftMax 後,它們所對應的值為 0,就可以 Masked 掉它們對應的 V , 第二次輸出為「am」。
第二次運算的結果如下圖所示: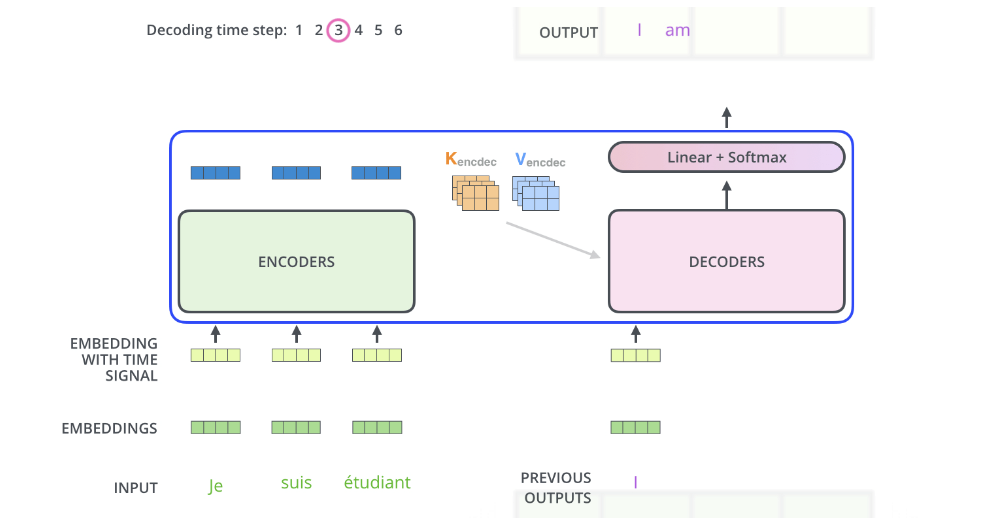
以此類推,一直到解碼器的輸出為 為止。最終的結果如下圖: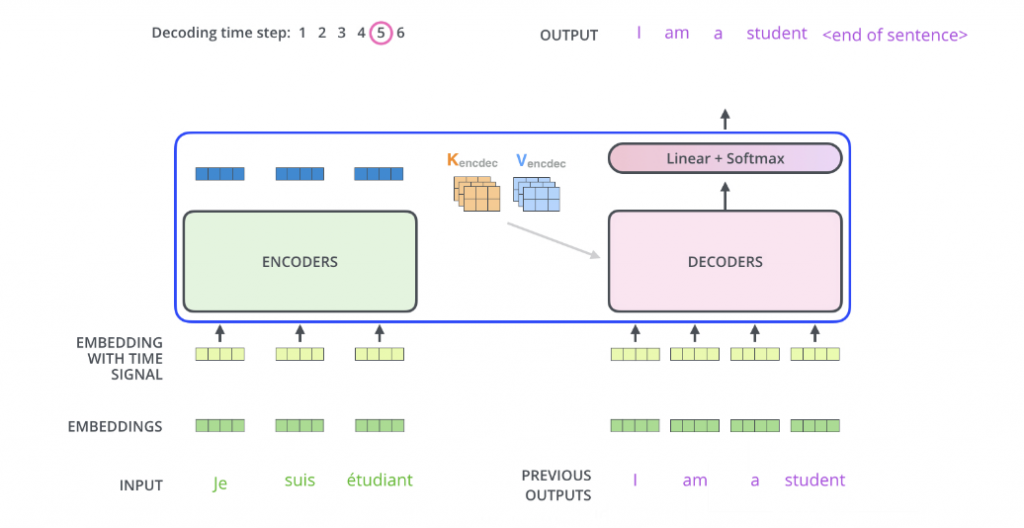
解碼器的後端附加了 Linear 層及 Softmax 層,用來將解碼器的輸出轉換成對應的文字。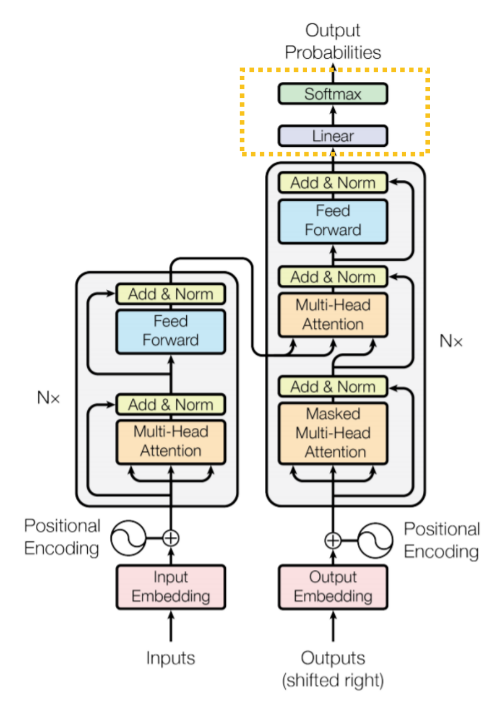
解碼器的輸出是一個浮點數向量,經過一個 Linear 層,輸出為一個 logits 向量,此一向量的長度即是輸出語言的字彙數量,每一個位置代表一個字。假設我們的輸出為一 10000 字的英文字彙集合,那麼 logit 向量的長度即為 10000。
再經過 Softmax 處理,則輸出為一機率分布向量,代表每一個對應文字的機率。通常最高機率的那一個字,即被選為此次的輸出單字。整個操作如下圖所示: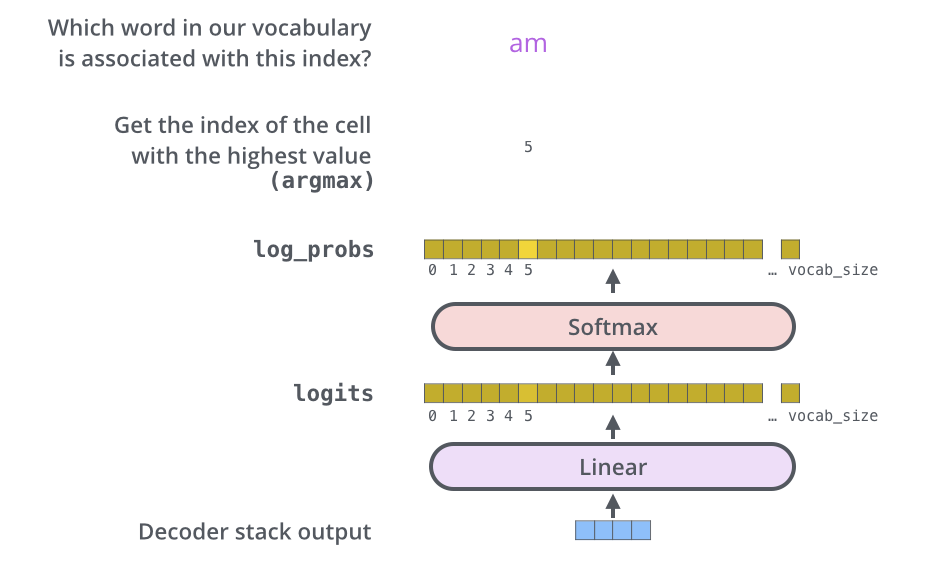
最後,就以一個編碼解碼各只有兩層的簡化 Transformer 來整體的看一下這個模型。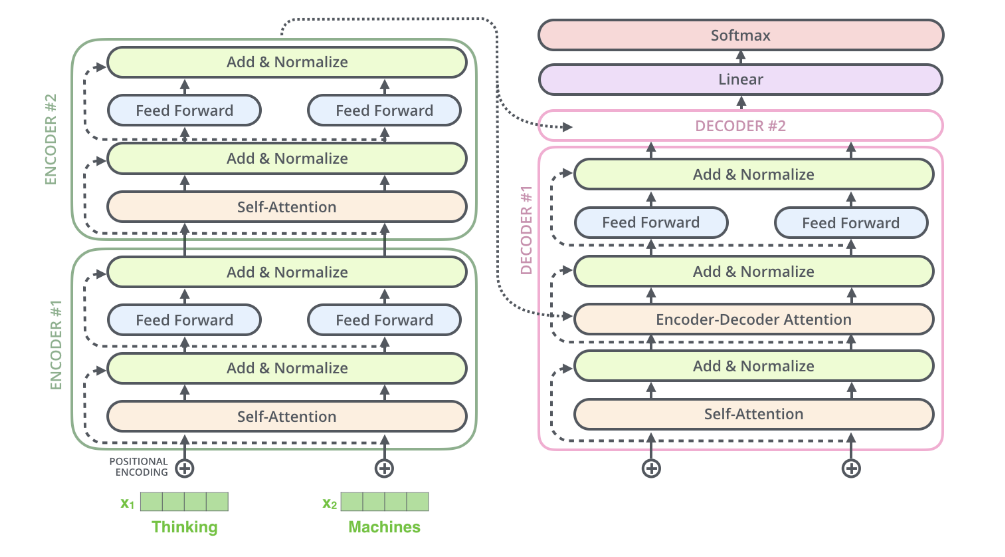
(註一:在論文中,作者引用了下列 sequence-to-sequence 模型論文:
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly
learning to align and translate. CoRR, abs/1409.0473, 2014.
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017)
(註二:本節中的圖形,皆源自 Jay Alammar 的《The Illustrated Transformer》 )


 iThome鐵人賽
iThome鐵人賽